Superseded numbers — canonical-target re-estimation (June 4, 2026)
This analysis note documents a historical run under the earlier validation label. On June 4, 2026 the paper adopted a reproducible, non-circular target (651 always-loser cobidders; frequent-loser flag never used in the label) and re-estimated every result. Where this page conflicts with the paper or the changelog, the paper wins.
AN-029: Three-classifier timing battery — strict prospective evaluation¶
Intuition (plain-language)
The toughest timing test in the paper. Train the screen on only 2009–2015 (or 2009–2017) and grade it against cobidders whose cartels were adjudicated after 2019 — a target the training data could not have peeked at. It still lands AUC 0.79–0.89 across all six (window × target) combinations. Genuine prospective generalization: the loser-side footprint is informative about cartels the screen had no way of knowing about when it was built.
Question¶
Does the FL screen preserve discrimination under three progressively- earlier train windows, evaluated against both all-time and truly- out-of-time cobidder targets? The battery is the strongest within-data timing audit: three independent train horizons × two genuine out-of- sample evaluations.
Design¶
- Three classifiers, each frozen on a different training horizon:
- clf_2015: trained on always-losers as of 2009–2015 (N = 11,699; 127 cobidders observed in train).
- clf_2017: trained on always-losers as of 2009–2017 (N = 14,391; 161 cobidders observed in train).
- clf_2019_full: full pool 2009–2019 (N = 16,843; 193 cobidders) — the in-sample reference.
- Four ground-truth targets:
- cobid_all: all cobidders ever identified.
- cobid_post2019: cobidders linked to CADE cases adjudicated after the training window closes — truly out-of-time evidence.
- all_cade: all 47 direct defendants (scope check; small N in sub-windows).
- post_2019: direct defendants from post-2019 adjudications (very small N, mostly excluded from headline reading).
- Scores: FL14 binary flag;
tenders_countcontinuous.
Results¶
Headline: AUC × classifier × target¶
| Classifier | Target | Score | AUC | 95% CI | N+ |
|---|---|---|---|---|---|
| clf_2015 | cobid_all | FL flag | 0.791 | [0.752, 0.830] | 127 |
| clf_2015 | cobid_all | continuous | 0.851 | [0.821, 0.881] | 127 |
| clf_2015 | cobid_post2019 | FL flag | 0.786 | [0.731, 0.840] | 67 |
| clf_2015 | cobid_post2019 | continuous | 0.854 | [0.815, 0.893] | 67 |
| clf_2017 | cobid_all | FL flag | 0.856 | [0.829, 0.883] | 161 |
| clf_2017 | cobid_all | continuous | 0.897 | [0.877, 0.918] | 161 |
| clf_2017 | cobid_post2019 | FL flag | 0.844 | [0.806, 0.882] | 92 |
| clf_2017 | cobid_post2019 | continuous | 0.894 | [0.865, 0.923] | 92 |
| clf_2019_full (ref) | cobid_all | FL flag | 0.924 | [0.921, 0.926] | 193 |
| clf_2019_full (ref) | cobid_all | continuous | 0.939 | [0.932, 0.946] | 193 |
Direct-defendant scope check (small-N, reported for completeness)¶
| Classifier | Target | Score | AUC | 95% CI | N+ |
|---|---|---|---|---|---|
| clf_2015 | all_cade | FL flag | 0.676 | [0.457, 0.895] | 6 |
| clf_2017 | all_cade | FL flag | 0.638 | [0.440, 0.836] | 7 |
| clf_2019_full | all_cade | FL flag | 0.633 | [0.435, 0.831] | 7 |
CIs include 0.5 in every row. The direct-defendant null (AN-007: AUC 0.491 over the full 47-firm positive class) is statistically silent under strict-window evaluation because only 6–7 direct defendants are active in each window — too few positives for a tight AUC estimate. The null reading still holds; the small-N variant just cannot reject it.
Source: output/strict_prospective_summary.csv.
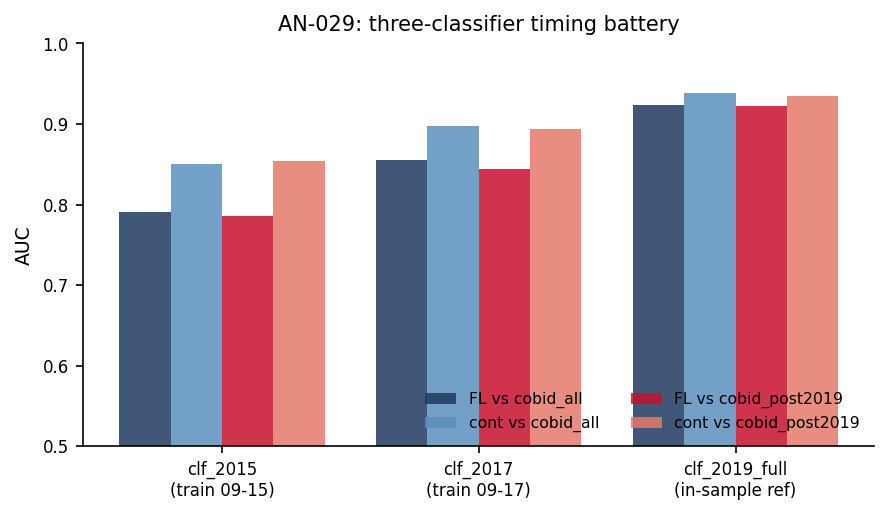
Figure: AUC across three classifiers (clf_2015, clf_2017, clf_2019_full) × two cobidder targets (cobid_all, cobid_post2019), for both FL14 binary and continuous log_tc. Even the strictest classifier (clf_2015) preserves AUC 0.79 (FL14) and 0.85 (continuous) against truly out-of-time cobid_post2019 cobidders.
Interpretation¶
The three-classifier battery converts H4 from "single-train-window result" to "robust across multiple train windows and against truly out-of-time positives". Five readings:
-
The headline AUC is preserved across three train horizons. FL flag: 0.791 → 0.856 → 0.924 (clf_2015 → clf_2017 → clf_2019_full). Continuous: 0.851 → 0.897 → 0.939. Monotonic increase as training data grows; no collapse at any horizon.
-
The truly out-of-time target preserves the result. cobid_post2019 cobidders are defined by CADE cases adjudicated AFTER even the clf_2017 training window — they cannot be in the training data by construction. The FL flag still gives AUC 0.786 (clf_2015) and 0.844 (clf_2017); continuous gives 0.854 and 0.894. The discrimination survives the strictest possible timing discipline available in the panel.
-
Continuous dominates binary in every cell. Same pattern as AN-011: continuous AUC exceeds FL flag AUC in all 6 cobidder cells. The dominance is not a sample-specific artifact.
-
Direct-defendant scope null persists but becomes statistically silent. clf_2015 and clf_2017 evaluations have only 6-7 direct defendants. AUCs around 0.63-0.68 with CIs that span [0.44, 0.90]. Cannot reject the null at standard thresholds, but cannot reject loser-side scope either. The full 47-defendant evaluation (AN-007) gives the cleaner read.
-
The drop relative to in-sample is documented and bounded. Going from clf_2019_full (FL 0.924) to clf_2015 (FL 0.791), the AUC drops ~0.13 — comparable to the OOF drop in AN-014 (0.995 → 0.891) and consistent with the temporal-holdout retention reported in AN-013 (~53% precision retention).
Follow-ups¶
- Re-run with even earlier train windows (clf_2013, clf_2010) to map the full timing-attenuation curve.
- Cross-validate the clf_2015 → cobid_post2019 result with bootstrap CIs.
- Add macros
\valClfFifteenFL,\valClfFifteenTC,\valClfSeventeenFL,\valClfSeventeenTC,\valClfFifteenPost2019FL, etc. to thescripts/99_make_paper_values.Rpipeline.