Superseded numbers — canonical-target re-estimation (June 4, 2026)
This analysis note documents a historical run under the earlier validation label. On June 4, 2026 the paper adopted a reproducible, non-circular target (651 always-loser cobidders; frequent-loser flag never used in the label) and re-estimated every result. Where this page conflicts with the paper or the changelog, the paper wins.
AN-013: Precision@k audit — temporal holdout vs in-sample¶
Intuition (plain-language)
In-sample precision is inflated because the screen has already seen the data it is graded on. Under an honest train-on-past, test-on-future split, precision@500 falls from 0.132 to 0.070 (53% retained) and lift from 11.5× to 6.1×. The honest operational number is about half the headline — and the paper reports both columns side by side, resting its claims on the lower one. Roughly half the in-sample ranking power came from cases already under investigation when the data were generated.
Question¶
What are the temporal-holdout precision@k and lift metrics, and how much does the in-sample evaluation inflate operational numbers? The audit documents the gap honestly.
Design¶
- Sample: 16,843 always-losers in BEC 2009–2019.
- Split: train 2009–2016, test 2017–2019.
- Metrics: precision@k, recall@k, lift in both columns (in-sample, temporal holdout); retention = (temporal / in-sample).
Results¶
| k | precision@k (in-sample) | precision@k (temporal holdout) | retention | lift (in-sample) | lift (TH) |
|---|---|---|---|---|---|
| 50 | 0.300 | 0.020 | 7% | 26.2× | 1.7× |
| 100 | 0.170 | 0.070 | 41% | 14.8× | 6.1× |
| 200 | 0.160 | 0.076 | 48% | 14.0× | 6.6× |
| 500 | 0.132 | 0.070 | 53% | 11.5× | 6.1× |
| 1000 | 0.097 | 0.066 | 68% | 8.5× | 5.8× |
Recall@k (temporal holdout): @500 = 18.1%; @1000 = 34.2%.
Macros: \valPrecInSFivehu (0.132), \valPrecTHFivehu (0.070),
\valLiftInSFivehu (11.5×), \valLiftTHFivehu (6.1×),
\valOpRetentionFiveHund (53%), \valOpInflationShare (47%),
\valOpRecallFiveHund (18%), \valOpRecallThou (34%).
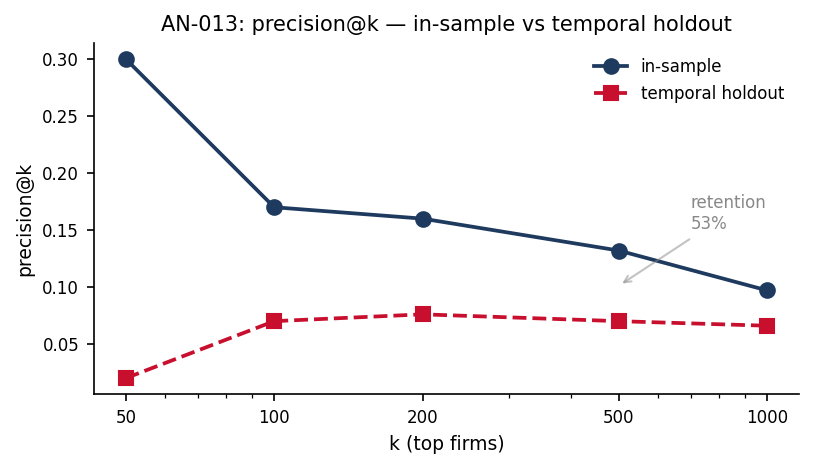
Figure: precision@k under in-sample evaluation (navy) vs temporal- holdout evaluation (red), k = 50 to 1,000. The gap is largest at k=50 (0.300 vs 0.020) and narrows at high k. At k=500, in-sample is 0.132 and temporal-holdout is 0.070 — retention 53%, the operational calibration number.
Interpretation¶
Verdict: INFLATED in-sample. Operational deployment metrics are roughly half the in-sample upper bounds:
- precision@500 retains 53% under temporal holdout (0.070 vs 0.132);
- lift retains 53% (6.1× vs 11.5×);
- recall@500 is 18% (vs ~34% in-sample at the same k).
Source of inflation: ~47% of the top-500 ranking comes from 2017–2019 participation, after CADE investigation was already underway for some of the cartels. The screen is therefore half prospective, half retrospective in the in-sample regime.
The paper reports both columns in the operational metrics table; the text relies on the temporal-holdout column for the operational claim. AUC firm-level under temporal holdout (0.864, see AN-014) is the honest discriminating performance number.
Follow-ups¶
- Compare with strict prospective-only deployment under alternative train windows (AN-006).
- Headcount analysis at k = 500 cutoff (35 cobidders flagged operationally).
- Sensitivity to k under each evaluation regime.