Superseded numbers — canonical-target re-estimation (June 4, 2026)
This analysis note documents a historical run under the earlier validation label. On June 4, 2026 the paper adopted a reproducible, non-circular target (651 always-loser cobidders; frequent-loser flag never used in the label) and re-estimated every result. Where this page conflicts with the paper or the changelog, the paper wins.
AN-012: Operational metrics — in-sample precision@k¶
Intuition (plain-language)
Turn the screen into a regulator's priority list: of the top 500 flagged firms, 13% are cobidders — an 11.5× lift over the base rate — and the FL14 cutoff alone shrinks the expensive bid-microdata pool by ~83%. That is real concentration of scarce investigative attention. But these are in-sample numbers with full hindsight, so they flatter the tool; AN-013 re-runs them under a real-time split before any operational claim is allowed to stand.
Question¶
What are the in-sample precision@k and lift metrics for the FL ranking used as a forensic gatekeeper? These are the upper-bound numbers that the temporal-holdout audit (AN-013) disciplines.
Design¶
- Sample: 16,843 always-losers in BEC 2009–2019.
- Positive class: 193 cobidders (AN-003).
- Metrics:
- precision@k: share of cobidders in top-k.
- recall@k: share of total cobidders captured.
- lift: precision@k / baseline cobidder rate.
Results¶
| k | precision@k | recall@k | lift |
|---|---|---|---|
| 50 | 0.300 | 0.078 | 26.2× |
| 100 | 0.170 | 0.088 | 14.8× |
| 200 | 0.160 | 0.207 | 14.0× |
| 500 | 0.132 | 0.342 | 11.5× |
| 1000 | 0.097 | 0.503 | 8.5× |
Pool-reduction headline: at the FL14 cutoff (2,735 firms), the bid-microdata pool needed for the forensic stage drops by approximately 83% while recovering 131 of 193 cobidders (~68%).
Macros: \valPrecInSFifty, \valPrecInSHund, \valPrecInSTwofh,
\valPrecInSFivehu, \valPrecInSOnek, plus the matching \valRecInS*
and \valLiftInS* series.
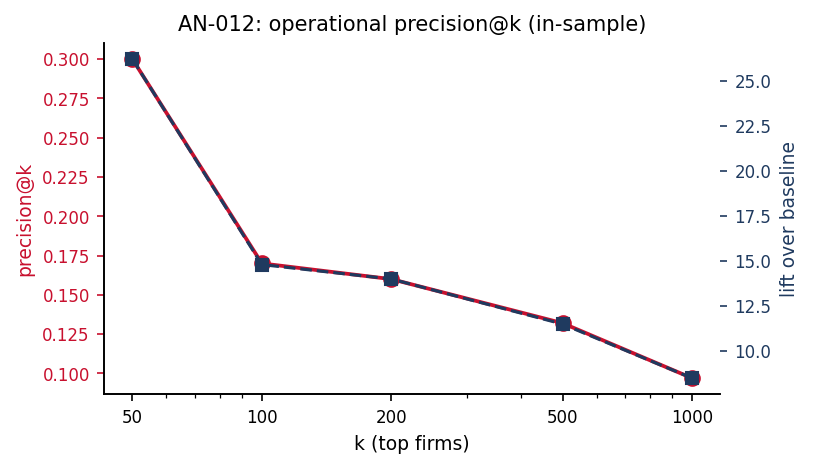
Figure: in-sample precision@k (red, left axis) and lift (navy, right axis) for k = 50, 100, 200, 500, 1000. Both decline monotonically as k expands the top-k pool with non-cobidders. The lift line shows the multiple over baseline cobidder rate.
Interpretation¶
The in-sample numbers are the upper bound: ~13% of the top-500 flagged-firms are cobidders, ~11× the baseline rate. As operating metrics, however, these are inflated — see AN-013 for the temporal-holdout column. The operational headline of the paper relies on the audited numbers, not these.
The 83% pool-reduction figure is robust (it is a property of the ranking + cutoff, not of the evaluation regime); the precision calibration changes between in-sample and audited regimes.
Follow-ups¶
- Sensitivity to k (especially around the FL14 cutoff at k ≈ 2,735).
- Operational headcount: at k = 500, the gatekeeper flags
\valOpFlaggedFiveHund= 35 cobidders, a manageable forensic workload. - Compare with the joint-scoring upper bound (AN-010).